Sourcegraph Cody vs Depwire CLI: Two Very Different Answers to the Same Question
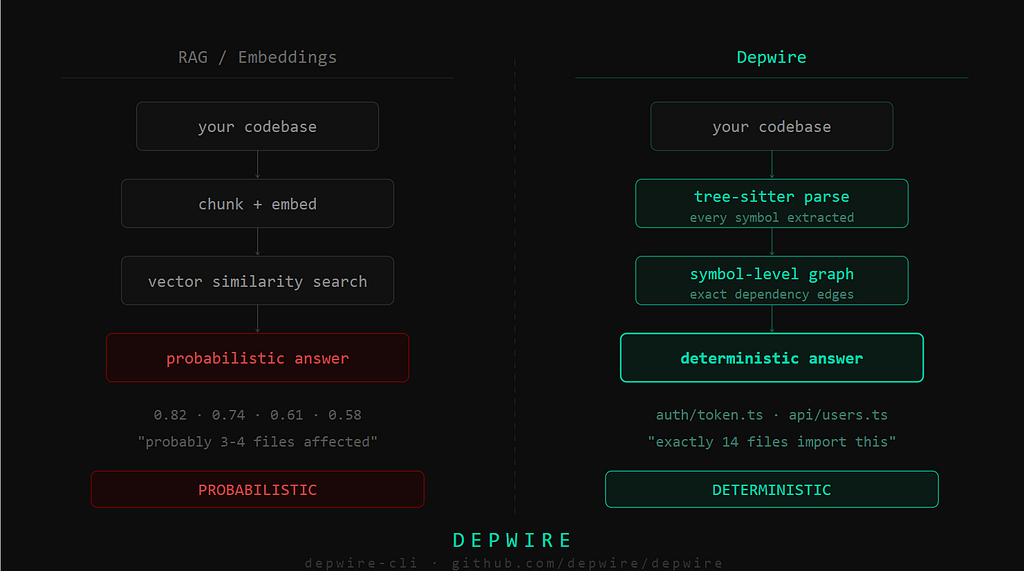
Both tools exist to answer the same question: “What does my AI coding assistant actually know about my codebase?”
The answers they give — and how they arrive at them — could not be more different.
The problem both tools are solving
AI coding agents are making consequential decisions about your codebase with incomplete structural knowledge. They read files linearly. They guess at dependencies. They produce confident answers and — increasingly — confident actions based on whatever happened to fit in their context window.
The result is a predictable failure mode that every engineering team eventually hits: an AI-generated change that is locally correct but globally destructive. The function signature looks right. The import compiles. Three files you were not looking at are now silently broken.
Sourcegraph Cody and Depwire CLI both try to solve this. They take fundamentally different architectural approaches, and understanding the difference matters more than most comparison articles acknowledge.
How Sourcegraph Cody works
Cody’s approach is retrieval-augmented. According to Sourcegraph’s own documentation, Cody splits your codebase into searchable chunks and converts them into vector embeddings. When you ask a question, your query is embedded into the same vector space, and the system retrieves chunks whose vectors are closest to your query. Those chunks become the context fed to the underlying language model.
Sourcegraph has since evolved beyond pure embeddings for their Enterprise tier — they now use their own code search infrastructure alongside semantic retrieval to improve context quality. The fundamental mechanism remains the same: similarity-based retrieval feeding an LLM that reasons over what it receives.
This is a sophisticated, well-engineered approach to a genuinely hard problem. The retrieval quality is real. The cross-repository search is powerful at scale. For teams already invested in the Sourcegraph ecosystem, the integration is seamless.
The limitation is architectural, not executional. Similarity-based retrieval returns what looks relevant. It does not return what is structurally connected.
Those are different things.
How Depwire CLI works
Depwire does not retrieve. It traverses.
DETERMINISTIC, NOT PROBABILISTIC.
Depwire uses tree-sitter — the same parser powering GitHub’s code intelligence across millions of repositories — to parse every file and extract exact structural facts: every function definition, every class, every interface, every import statement and what it resolves to, every export and who consumes it.
The result is a symbol-level dependency graph. Not an approximation. Not a semantic index. An exact map of every connection in your codebase, represented as a directed graph where nodes are symbols and edges are dependency relationships.
When you ask “what breaks if I delete src/utils/encode.ts?", Depwire does not search for chunks that look related to that file. It traverses every incoming edge to that node, then every incoming edge to those nodes, recursively, until the full blast radius is computed. The answer is exact: 30 broken imports across 18 files. Not "probably 3-4." Exactly 30. Named.
This is graph traversal over a verified data structure. The answer is as deterministic as a compiler — because it uses the same class of technique.
The “What If” test
This is where the architectural difference becomes concrete and consequential.
Ask Cody: “What breaks if I delete src/utils/encode.ts?"
Cody will retrieve chunks related to that file and ask the underlying LLM to reason about what might be affected. The answer will be informed, plausible, and incomplete. The LLM cannot know about import chains it has not seen. The retrieval system cannot guarantee it found every consumer of every symbol in that file. The answer is a best estimate.
Run Depwire’s What If simulation on the same file:
depwire whatif . --simulate delete --target src/utils/encode.ts
The browser UI opens automatically. Two arc diagrams side by side. Left: current state — the full dependency graph in full color. Right: after simulation — 92% of the graph dimmed to 8% opacity, 30 broken connections rendered in red (#ef4444), the 18 affected nodes glowing with a red drop shadow. The health score delta: -8 points.
There is no estimate here. There is a graph traversal with a verified result.
The security dimension
Depwire’s graph-aware security scanner adds another layer to this comparison that retrieval-based tools cannot replicate.
A shell injection pattern in a file with zero external connections scores Low. The same pattern in a file reachable from an unauthenticated HTTP route scores Critical. Depwire runs the dependency graph in reverse — given a vulnerable function, which external entry points can reach it? — and elevates severity based on actual reachability, not pattern match severity alone.
Running depwire security . against honojs/hono (352 TypeScript files):
6 Critical
19 High
14 Medium
1 Low
Not because of how many patterns were found. Because of which patterns are reachable from which entry points. This is the difference between alert fatigue and actionable intelligence.
Retrieval-based tools can surface security-adjacent code snippets. They cannot compute reachability through a verified dependency graph, because they do not have one.
Honest strengths of each approach
Sourcegraph Cody is better at:
- Natural language questions about code concepts (“explain how this authentication flow works”)
- Cross-repository search at enterprise scale
- Integration with the broader Sourcegraph ecosystem
- Questions where semantic similarity is the right retrieval signal
- Mature enterprise deployment with compliance and self-hosting options
Depwire CLI is better at:
- Exact dependency analysis (“what imports this symbol?”)
- Blast radius computation before making changes
- Graph-aware security vulnerability prioritization
- Answering “what breaks if I do X?” with verified precision
- Architecture health scoring with dimension-level breakdown
- Dead code detection based on actual graph connectivity
These are not the same use cases. Cody is optimized for helping you understand and write code. Depwire is optimized for knowing the structural consequences of changes to existing code.
When it matters most
The moment this distinction becomes critical is when AI agents move from suggesting to acting.
When an AI assistant is proposing code in a chat window, probabilistic context is often good enough. When an AI agent is autonomously deleting files, renaming functions across 47 references, or restructuring modules — you need to know the exact blast radius, not an estimate.
This is where we are heading. GPT-5.5 shipped this week with Agent-to-Agent streaming. GitHub’s gh aw CLI lets architects define repository automation in Markdown. Claude's autonomous coding capabilities are expanding with every release.
The agents are getting more autonomous. The cost of an incorrect blast radius estimate is increasing proportionally.
Both in the same stack
These tools are not mutually exclusive. Many developers use Cody or Cursor for active coding assistance — natural language queries, autocomplete, chat-based exploration — while using Depwire’s 17 MCP tools to give any AI assistant verified structural context before making architectural changes.
The two approaches complement each other. Retrieval gives the AI semantic understanding. Graph traversal gives it structural truth.
npm install -g depwire-cli
TypeScript, JavaScript, Python, Go, Rust, C, C#, Java, C++, Kotlin, PHP. Zero configuration. Works with Claude, Cursor, VS Code Copilot, and any MCP-compatible AI tool.
github.com/depwire/depwire
Have you used both approaches in the same workflow? What did you find?